Context Guided Transformer Entropy Modeling for Video Compression
{kind=link}
Abstract
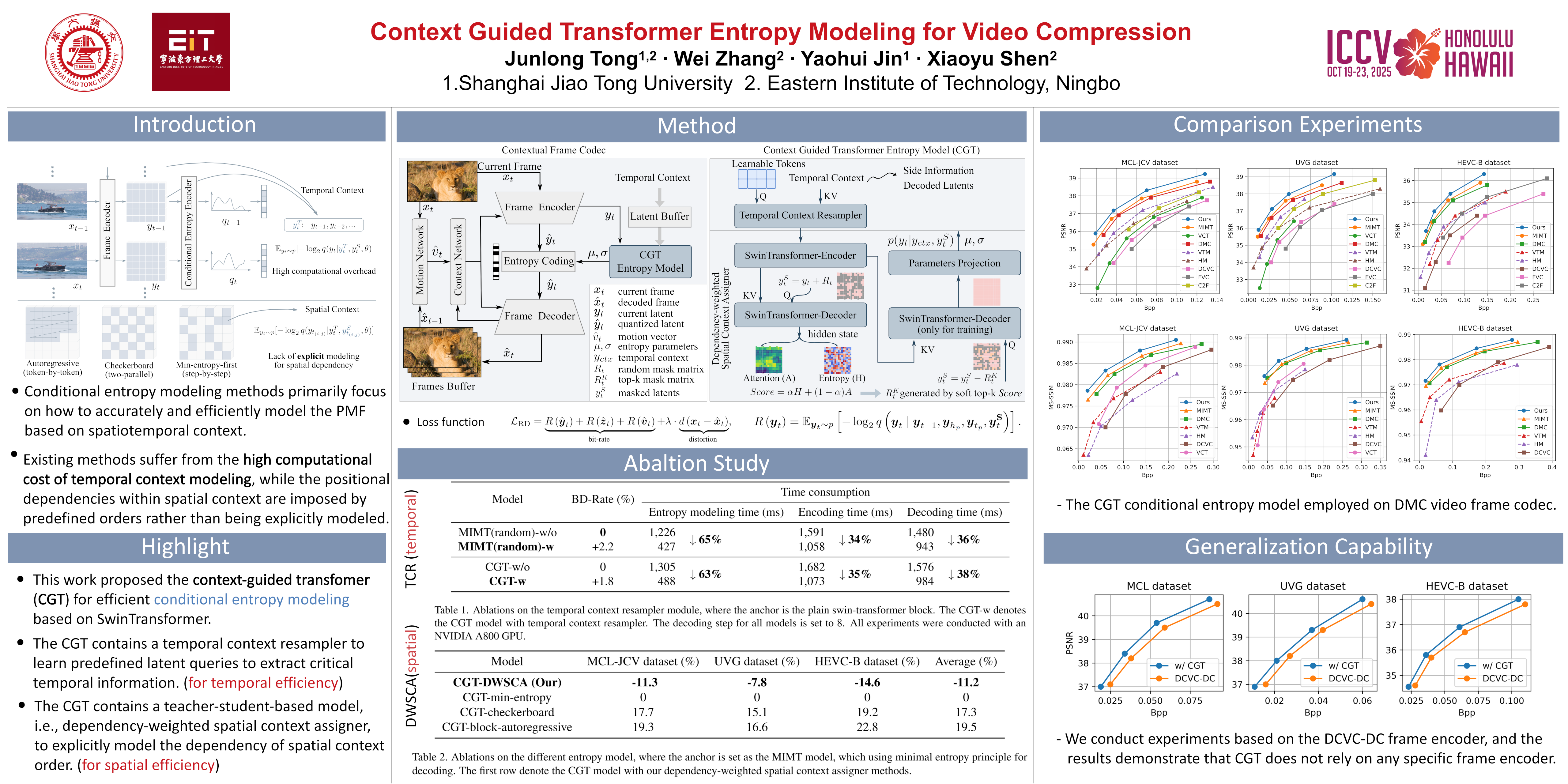
Conditional entropy models effectively leverage spatio-temporal contexts to reduce video redundancy. However, incorporating temporal context for entropy models often relies on intricate model designs, increasing complexity and computational costs. Furthermore, entropy models employing autoregressive or checkerboard strategies fail to model the significance of spatial context order, potentially limiting the availability of relevant contextual information during decoding. To address these issues, we propose the context guided transformer (CGT) entropy model, which estimates probability mass functions of the current frame conditioned on resampled temporal and importance-weighted spatial contexts. The temporal context resampler learns predefined latent queries and utilizes transformer encoders to fuse the resampled critical information while reducing subsequent computational overhead. Subsequently, we design a teacher-student network to explicitly model the importance of spatial context order. During training, the teacher network generates an attention map (i.e., importance scores) and an entropy map (i.e., confidence scores) from randomly masked inputs, guiding the student network to select top-k weighted decoding tokens as subsequent contextual information. During inference, only the student network is employed, utilizing high-importance and high-confidence tokens to guide the prediction of the remaining undecoded tokens. Experimental results demonstrate that our CGT model reduces entropy modeling time by approximately 65\% lowers the BD rate by 11\%, compared to the previous SOTA conditional entropy model.