CapeLLM: Support-Free Category-Agnostic Pose Estimation with Multimodal Large Language Models
{kind=link}
Abstract
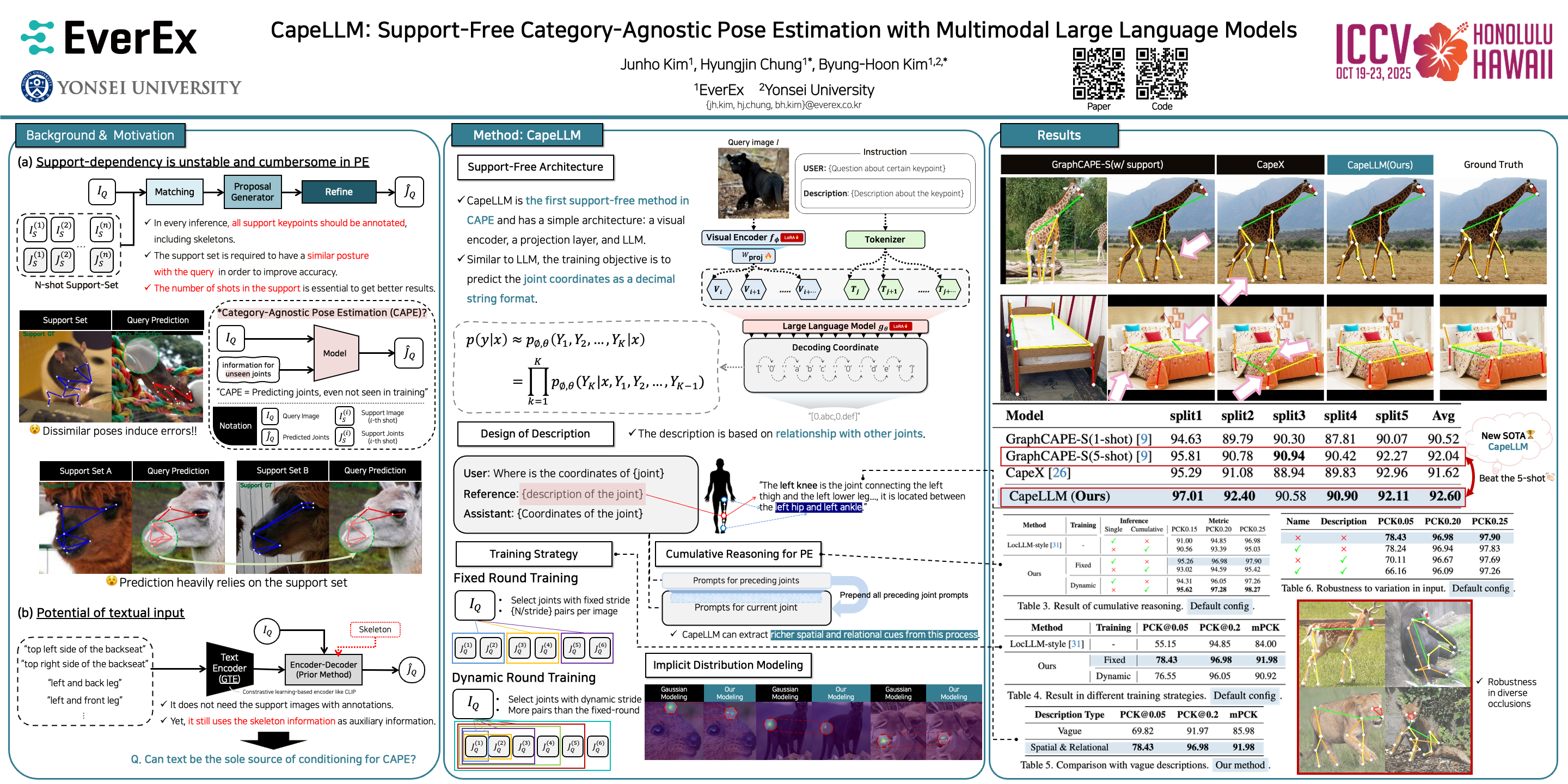
Category-agnostic pose estimation (CAPE) has traditionally relied on support images with annotated keypoints, a process that is often cumbersome and may fail to fully capture the necessary correspondences across diverse object categories. Recent efforts have explored the use of text queries, leveraging their enhanced stability and generalization capabilities. However, existing approaches often remain constrained by their reliance on support queries, their failure to fully utilize the rich priors embedded in pre-trained large language models, and the limitations imposed by their parametric distribution assumptions. To address these challenges, we introduce CapeLLM, the first multimodal large language model (MLLM) designed for CAPE. Our method only employs query image and detailed text descriptions as an input to estimate category-agnostic keypoints. Our method encompasses effective training strategies and carefully designed instructions for applying the MLLM to CAPE. Moreover, we propose an inference mechanism that further enhances the reasoning process for unseen keypoints. while flexibly modeling their underlying spatial distribution and uncertainty, allowing for adaptive refinement based on contextual cues. We conducted extensive experiments to apply the MLLM to CAPE effectively, focusing not only on the model architecture and prompt design but also on ensuring robustness across input variations. Our approach sets a new state-of-the-art on the MP-100 benchmark in the 1-shot and even 5-shot setting, marking a significant advancement in the field of category-agnostic pose estimation.