Breaking the Encoder Barrier for Seamless Video-Language Understanding
{kind=link}
Abstract
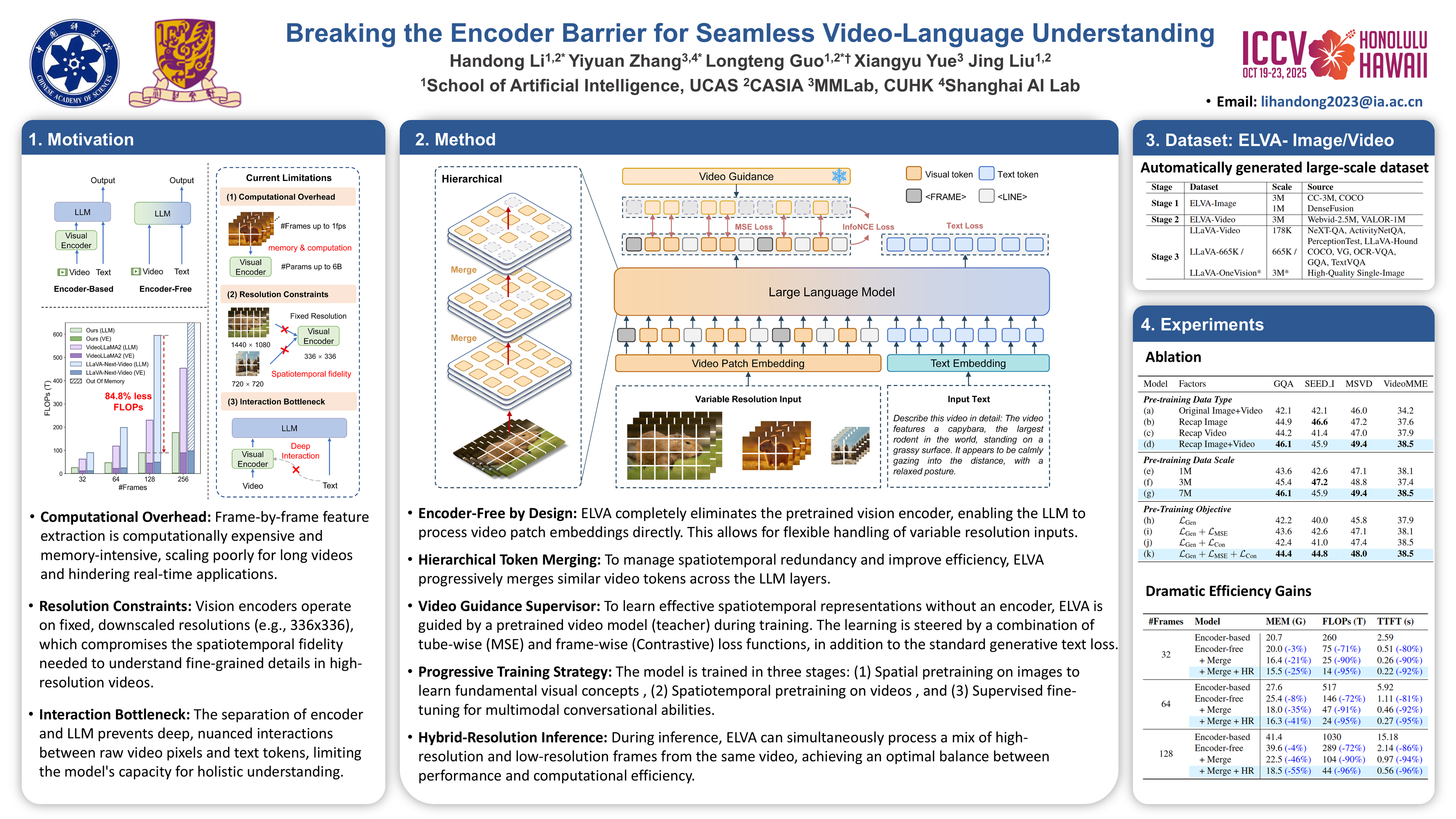
Most current video-language models rely on an encoder-decoder architecture, where a vision encoder extracts visual features from video and passes them to a language model. However, this approach suffers from inefficiencies, resolution biases, and challenges in capturing fine-grained multimodal correlations, particularly when dealing with long-duration videos. To address these limitations, we propose NOVA, an encoder-free video-language model that directly integrates raw video input into a language model, eliminating the need for a separate vision encoder. NOVA leverages input-adaptive video tokenization, efficient distillation from a video-pretrained teacher, multimodal alignment using synthetic video recaption data, and hybrid-resolution inference to overcome the limitations of traditional models. Our experiments demonstrate that NOVA, with only about 10M publicly available training data, achieves competitive performance as strong encoder-based models across various benchmarks, and offers clear advantages in efficiency and scalability. This work provides a promising solution for real-time, large-scale video applications and paves the way for more flexible and resource-efficient video-language models.