Text2Outfit: Controllable Outfit Generation with Multimodal Language Models
{kind=link}
Abstract
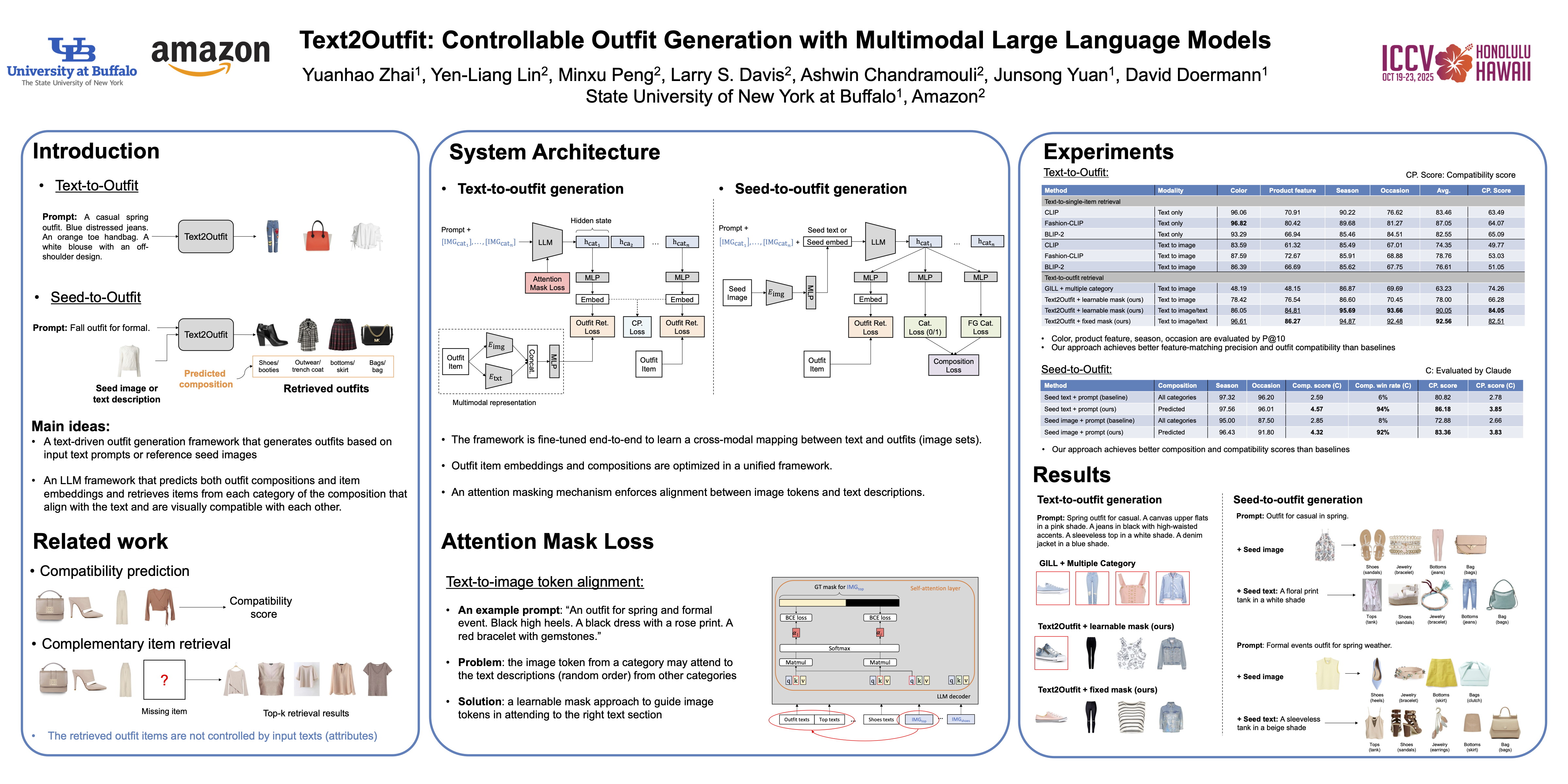
Existing outfit recommendation frameworks mainly focus on outfit compatibility prediction and complementary item retrieval. However, the outfit items are predicted by the pre-trained model and can not be controlled by the text prompt. We present a text-driven outfit generation framework, Text2Outfit, which generates outfits controlled by the text prompt. Our framework supports two forms of outfit recommendation: 1) text-to-outfit generation, which retrieves the outfits given the prompt, where the prompt includes the specification of the entire outfit (e.g., occasion or season) and the individual outfit items (e.g., product feature), and 2) seed-to-outfit generation, which additionally uses a seed item (image or item descriptions) as input and retrieves items to build outfits. We train a large language model framework (LLM) to predict a set of embeddings to retrieve outfit items. We devise an attention masking mechanism in LLM to handle the alignment between the outfit text descriptions in the prompt and the image tokens from different categories. We conducted the experiments on the Poylvore data set and evaluated outfit retrieval performance from two perspectives: 1) feature matching for outfit items and 2) outfit compatibility. The results show that our approach achieves significantly better performance than the baseline approaches for text to outfit retrieval task.